小视科技团队开源的基于 RGB 图像的活体检测模型,是专门面向工业落地场景,兼容各种复杂场景下的模型。该自研的剪枝轻量级模型,运算量为 0.081G,在麒麟 990 5G 芯片上仅需 9ms。同时基于 PyTorch 训练的模型能够灵活地转化成 ONNX 格式,实现全平台部署。
如今,人脸识别已经进入我们生活中的方方面面:拿起手机扫脸付账、完成考勤、入住酒店等,极大地便利了我们的生活。
我们在享受技术带来方便的同时,也要应对其潜在的风险。一旦虚假人脸攻击成功,极有可能对用户造成重大损失。
如 2019 年,在拉斯维加斯举办的世界黑帽(Black Hat)安全大会上,腾讯公司的研究人员就曾演示用一副特制眼镜攻破苹果 Face ID。
更早之前,也有人曾使用 3D 打印「石膏」人脸攻击手机的人脸识别功能,成功破解多款人脸识别解锁功能。

为了抵御这种假脸攻击,小视科技团队开源了一个静默活体检测算法和可适用于安卓平台的部署源码,可兼容各种工业级复杂场景的活体检测。
静默活体检测算法项目地址:
https://github.com/minivision-ai/Silent-Face-Anti-Spoofing
安卓平台部署源码项目地址:
https://github.com/minivision-ai/Silent-Face-Anti-Spoofing-APK
活体检测技术主要是判别镜头前出现的人脸是真实的还是伪造的,其中借助其他媒介呈现的人脸都可以定义为虚假的人脸,包括打印的纸质照片、电子产品的显示屏幕、硅胶面具、立体的 3D 人像等。活体检测技术能够抵御各种假脸的攻击,为人脸识别保驾护航。
目前主流的活体解决方案分为配合式和非配合式活体,配合式活体需要用户根据提示做出相应的动作从而完成判别,而非配合式活体在用户无感的情况下直接进行活体检测,具有更好的用户体验。
非配合式活体根据成像源的不同一般分为红外图像、3D 结构光和 RGB 图像三种技术路线:红外图像滤除了特定波段的光线,天生抵御基于屏幕的假脸攻击;3D 结构光引入了深度信息,能够很容易地辨别纸质照片、屏幕等 2D 媒介的假脸攻击;RGB 图片主要通过屏幕拍摄出现的摩尔纹、纸质照片反光等一些细节信息进行判别。基于以上分析不难发现,基于 RGB 图片的活体检测与其他两种方法相比,仅能通过图像本身的信息进行判别,在实际的开放场景中面临着更大的挑战性。
小视科技团队开源的基于 RGB 图像的活体检测模型,是专门面向工业落地场景,兼容各种复杂场景下的模型。该自研的剪枝轻量级模型,运算量为 0.081G,在麒麟 990 5G 芯片上仅需 9ms。同时基于 PyTorch 训练的模型能够灵活地转化成 ONNX 格式,实现全平台部署。
活体任务的定义
基于 RGB 图像的活体检测是一个分类任务,目标是有效地区分真脸和假脸,但又有别于其他类似于物品分类的任务。其中的关键点在于攻击源分布过于广泛,如图 1 所示:不同的攻击媒介,不同设备的成像质量,不同的输入分辨率都对分类结果有着直接的影响。为了降低这些不确定因素带来的影响,小视科技团队对活体的输入进行了一系列限制:活体的输入限制在特定的分辨率区间;输入图片均为实时流中截取的视频帧。这些操作大大降低了活体模型在实际生产部署上失控的风险,提升了模型的场景鲁棒性。
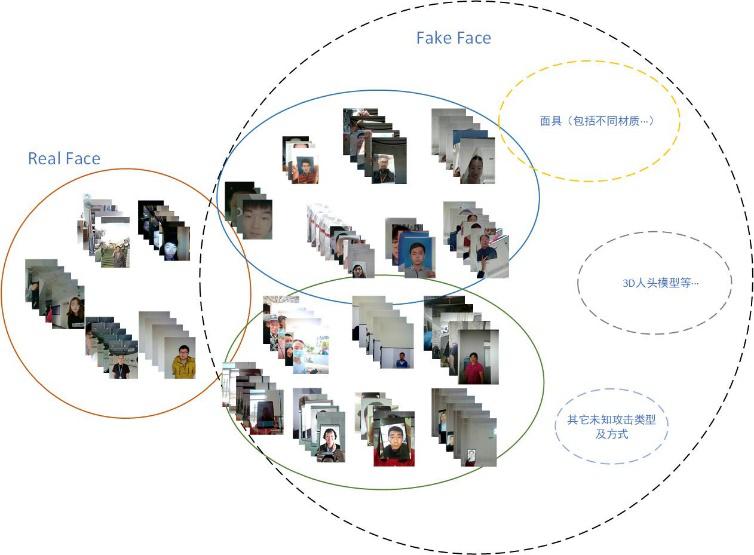
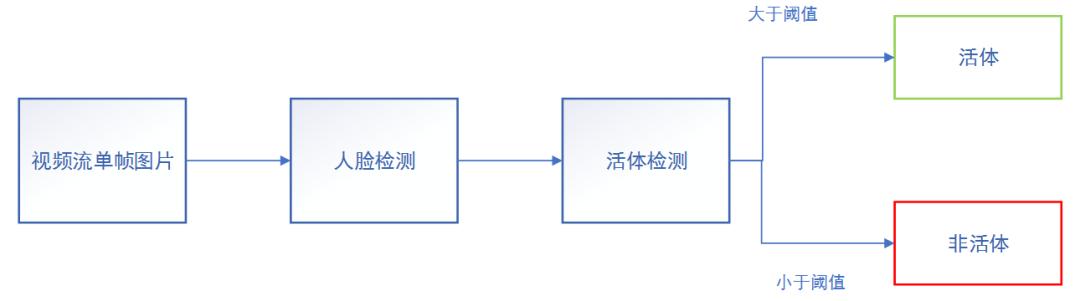
基于成像介质种类的不同,小视科技团队将样本分为真脸、2D 成像(打印照片,电子屏幕)以及 3D 人脸模具三类,根据上述的准则整理和收集训练数据。活体检测的主要流程如图 2 所示。
开源模型技术路线
小视科技团队采用自研的剪枝轻量级网络作为 backbone 训练模型,使用 Softmax + CrossEntropy Loss 作为训练分类的监督。使用不同尺度的图片作为网络的输入训练数据,增加模型间的互补性,从而进行模型融合。考虑到用于真假脸判别的有效信息不一定完全分布在脸部区域,可能在取景画面的任何地方(如边框,摩尔纹等),小视科技团队在 backbone 中加入了 SE(Squeeze-and-Excitation)的注意力模块,动态适应分散的判别线索。同时小视科技团队也通过实验发现真假脸在频域中存在明显的差异,为此引入傅里叶频谱图作为模型训练的辅助监督,有效提升了模型精度。
自研的轻量级剪枝网络
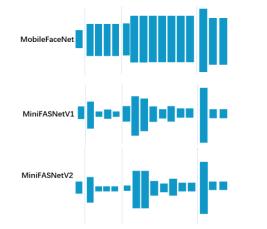
小视科技团队使用自研的模型剪枝方法,将 MoboileFaceNet 的 flops 从 0.224G 降低到了 0.081G,剪枝的网络结构如图 3 所示。模型观测误检率在十万一对应的真脸通过率,在精度没有明显损失的情况下,模型前向运行的速度提升了 40%。
注意力机制
考虑到用于真假脸判别的有效信息不一定完全分布在脸部区域,也有可能在取景画面的任何地方(如边框,摩尔纹等)。小视科技团队在 backbone 中加入了 SE(Squeeze-and-Excitation)的注意力模块,动态适应分散的判别线索,热力图如图 4 所示。对于假脸,模型更关注于边框信息和屏幕的摩尔纹信息,对于真脸更加关注脸部以及周围的信息。

数据预处理
使用人脸检测器获取图像中的人脸框坐标,按照一定比例 (scale) 对人脸框进行扩边,图 5 展示了部分 patch 的区域,为了保证模型的输入尺寸的一致性,将 patch 区域 resize 到固定尺寸。

傅里叶频谱图
将假脸照片与真脸照片转化生成频域图,对比发现假脸的高频信息分布比较单一,仅沿着水平和垂直方向延伸,而真脸的高频信息从图像的中心向外呈发散状,如图 6 所示。根据以上的实验,小视科技团队发现真脸和假脸的傅里叶频谱存在差异,从而引入了傅里叶频谱对模型训练进行辅助监督。

基于傅里叶频谱图的辅助网络监督
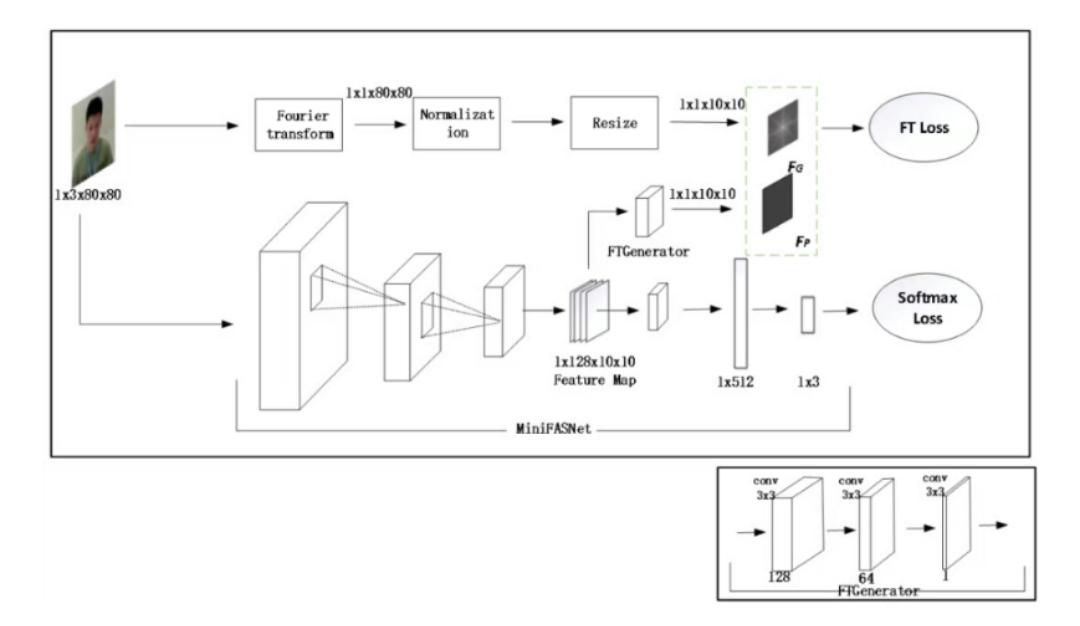
基于对于真脸和假脸在频域的观察分析,小视科技团队提出了基于傅里叶频谱图进行辅助网络监督的训练方法,整理架构图如图 7 所示。网络的主分支采用 Softmax+ CrossEntropy 作为网络的监督,如公式(1)所示。其中, f_j表示输出类别的第 j 个置信度, y_i 表示样本的真实标签,N 为训练样本的个数。
小视科技团队采用在线的方式生成傅里叶频谱图,使用 L2 Loss 作为损失函数。输入图片的尺寸为 3x80x80,从主干网络中提取尺寸为 128x10x10 特征图,经过 FTGenerator 分支生成 1x10x10 的预测频谱图 F_P 。通过傅里叶变换,将输入图片转化成频谱图,再进行归一化,最后 resize 成 1x10x10 尺寸得到 F_G ,使用 L2 Loss 计算两特征图之间差异,如公式(2)所示。
为了控制 L_FT在训练过程中对梯度的贡献作用,分别引入了
平衡两个损失函数L_Softmax和L_FT,如公式(3)所示,其中
。在实验中设置
。
其他模型策略
使用大体量网络 ResNet34 蒸馏剪枝网络 MiniFASNetV1 和 MiniFASNetV2,精度得到提升。
使用模型融合的机制,针对于不同输入尺度、不同网络结构以及不同迭代次数的模型进行融合,充分挖掘模型间对分类任务的互补性,提升模型精度。
实验结果
测试集建立
小视科技团队基于实际的生产场景建立了 100W 量级的测试集,从移动设备的视频流中实时获取图像。真脸数据包含了强光、暗光、背光、弱光以及阴阳脸等各种复杂场景。基于 2D 的假脸数据使用打印纸、铜版纸、照片纸以及电脑屏幕、平板 Pad 屏幕、手机屏幕,在不同的距离、角度和光线下进行采集。基于 3D 的假脸数据则采用头模、硅胶面具和纸质照片抠洞的人脸面具进行采集。
模型评价指标
小视科技团队采用 ROC 曲线作为模型的观测指标,控制十万一的误检率,保证模型在 97%+ 的通过率。与一般的分类任务不同,团队采用了 ROC 曲线而非分类精度作为度量指标,其原因是:生产落地场景对活体模型的误检控制具有很高的要求。
为了降低活体在应用场景发生误检的概率,小视科技团队控制模型误检率在十万一量级的同时,保证了较高的真脸通过率。团队将活体定义为三分类任务,为了适应 ROC 曲线的评价指标,将真脸以外的类别都定义成假脸,从而解决了使用 ROC 曲线适应多分类的问题。
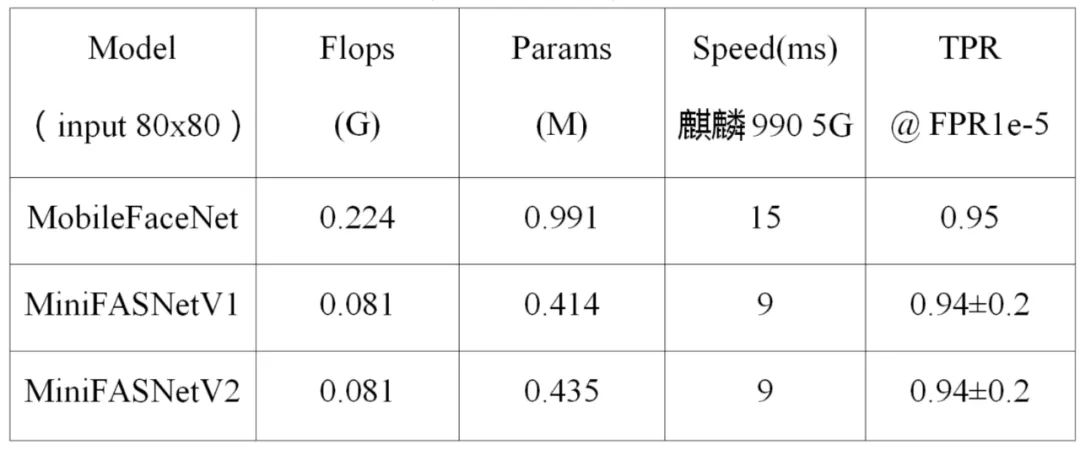
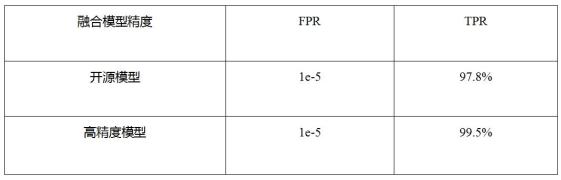
最终的开源融合模型,包含了两个剪枝网络的单模型,在测试集上的观测指标如表 2 所示。开源模型误检控制在 1e-5 的情况下,真脸通过率能够达到 97.8%。未开源的高精度模型在相同的误检率下,真脸通过率达到 99.5%。
速度指标
开源融合模型在不同芯片上速度指标如表 3 所示,在麒麟 990 5G 上仅需要 19ms。


为了方便开发者更好地体验该项静默活体检测技术,小视科技团队准备了用于测试的安卓端 APK,不仅可以直观地感受该项技术达到的效果,还可以实时观测速度、置信度等相关指标。
原标题:《人脸识别漏洞频出?这里有个开源静默活体检测算法,超低运算量、工业级可用》



